Segunda práctica de programación cliente-servidor en Perl
Asignatura: Sistemas Distribuidos. (Curso: 2001-2002)
Ingeniero Técnico en Informática.
| Esta práctica se entregará con el plazo límite
de tres semanas naturales a partir del momento de su publicación (19 de
Abril de 2002). La recepción de las prácticas se hará por correo
electrónico, por disquete, para lo cual se ruega que confirmen con el
profesor la recepción de la práctica (en el caso de correo
electrónico). Todo esto sin perjuicio de que el profesor pueda requerir
el alumno las explicaciones que considere oportunas sobre el
funcionamiento de la solución a la práctica. Las prácticas se
entregarán por parejas o individualmente, y son una condición importante
para obtener resultados positivos en la convocatoria ordinaria
correspondiente.
Al mismo tiempo, sin perjuicio, tan poco, de que el alumno pueda
requerir al profesor las explicaciones que considere oportunas sobre el
funcionamiento del enunciado de la práctica, en el horario de laboratorio
y tutorías.
|
-
Introducción
Queremos trabajar un poco con procesos y comunicación mediante sockets TCP y
UDP. La excusa es construir una aplicación distribuida que ponemos a prueba
mediante una especie de proxy WEB simplificado. La herramienta de
programación es el lenguaje Perl sobre UNIX, y aquí tenemos un ejemplo
de intermediario WEB que puede venir muy bien para que resolvais la
práctica: funciona para HTTPv1.0. (Aunque el que lo prefiera puede
hacerlo con Java!)
Desafortunadamente no ha sido posible instalar el módulo LWP en el
laboratorio, lo que hubiera simplificado grandemente las cosas, y nos tenemos
que conformar con el módulo NET.
Pero el sistema que se construirá será un poco más complicado. En la Figura
1 se muestra un esquema simplificado con las tareas involucradas:
Figura 1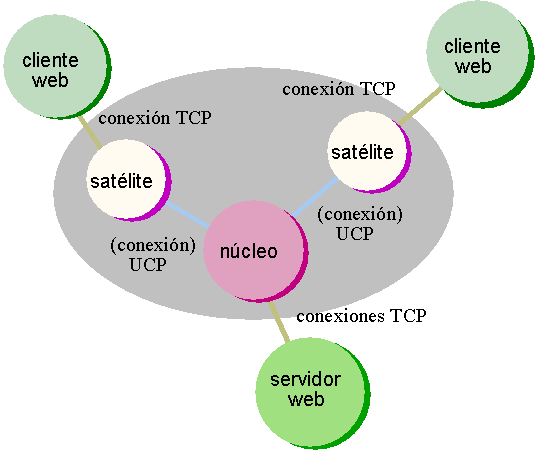
El intermediario proxy es el conjunto de satélites y el núcleo que
tenemos la misión de diseńar. Éste núcleo almacenará las páginas web que
hayan sido descargadas por los clientes en archivos locales de la máquina
donde reside el núcleo del proxy.
Cuando un cliente desea descargar una página, lo primero que hace es
comprobar si ya dispone de ella en su caché local, si no, intentará
descargarla del servidor. El truco, aquí, es que cuando alguno de los
clientes conectados a este servidor desee bajar una página, se comprobará si
otro cliente ya la ha obtenido anteriormente.
-
Discusión de las tareas involucradas en el problema
En primer lugar, un proxy sencillo deberá poder entrar en contacto con el
servidor WEB en nombre del cliente WEB. Esto implica tres operaciones:
a) configurar el cliente web para que utilice el proxy que hemos puesto en
marcha, sobre una máquina concreta y con un número de puerto concreto.
b) el proxy deberá decodificar la cabecera de la petición del cliente web
para poder establecer la comunicación por socket TCP/IP con el servidor.
Recuerde que en la versión 1.0 por cada recurso al que se accede se establece
y se cierra una conexión por socket TCP.
c) a partir de este momento el proxy debe comportarse de modo transparente, si
es que queremos hacer algo sencillo. Como es lógico, puentearemos aquellas
peticiones que queramos tratar localmente.
ciclo básico de operación
En nuestro caso, el satélite es el encargado de recibir la
conexión con el cliente web, tal y como se muestra en la Figura
2. Y con la información del método HTTPv1.0 (véase el RFC1945
en IETF) podemos saber si el método es GET
(para descargar recursos) y el URL del recurso concreto que queremos
descargar. En este URL figura el nombre o la dirección Internet del servidor,
así como su número de puerto. Ésta información se envíará al núcleo,
en una o varias tramas UDP (como sea pertinente), y se instruye a éste para
que establezca la conexión TCP correspondiente con el servidor web.
A continuación debemos trasvasar desde el satélite al servidor web toda
la información que envía el cliente, que será enviada, a su vez al servidor
web. Éste, a su vez, responderá de la manera que crea conveniente, y debemos
transmitir ésta respuesta al cliente, siguiendo el camino inverso, que se
describe en la Figura 2. Se emplearán en ello tantas tramas UDP como sea
necesario.
Figura 2. 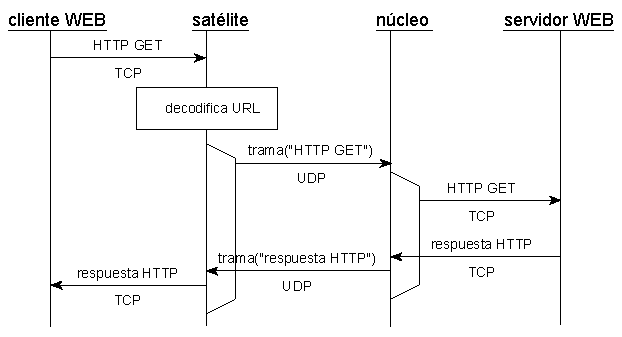
Cuando el núcleo recibe una petición GET desde el cliente que se refiere
a un recurso ya recuperado previamente, la retransmitirá desde su sistema de
archivos local. Observe que deberá retransmitir la respuesta completa que
daría el servidor en el caso de que la conexión fuera directa.
-
Problemas a tener en cuenta en el desarrollo de la aplicación
Como es normal, cada vez que se trata de resolver una tarea compleja, sobre
todo cuando estamos problemas nuevos y complejos, debemos acotar la
funcionalidad del sistema. Mi punto de vista particular, es empezar con un
sistema sencillo que tenga la funcionalidad básica, e ir incrementando sus
funciones. En esta lista no están enumerados todos los problema. Según vayan
apareciendo más, trataré de incluirlos aquí.
mantenimiento de la información en el caché
Las respuestas del servidor deberán soportarse mediante archivos. UNIX, y
Perl, por extensión, dispone de una función para generar nombres de archivos
únicos, para que no haya colisión de nombres. La asociación deberá
plasmarse en un array asociativo cuya clave será el nombre del recurso (URL),
y el contenido asociado a la clave, el nombre del archivo.
La siguiente pregunta es, żqué pasa cuando el proxy muere? żSe mantiene
el índice, en un archivo estático, junto al contenido de las respuestas del
servidor? Lo ideal es que fuera estático, pero todo depende de la complejidad
del resto de la aplicación. Si el servidor muere, lo ideal sería que al
poner en marcha de nuevo el proxy, se eliminara el caché anterior.
La siguiente pregunta es, żvamos a llenar el disco de archivos? Una
posible solución es poner un número límite de archivos. Teniendo en cuenta
el tamańo medio de los archivos, se podrá hacer una estimación sobre
2Mbytes o así.
De la solución de la pregunta anterior, dependerá la política de
desalojo de páginas de la caché.
de los procesos satélite
Cada proceso satélite permitirá la conexión con varios clientes web. Lo
normal es que en esta aplicación hubiera un cliente de caché local por cada
host de cliente web.
La siguiente pregunta es obvia żcómo aparecen los satélites en la
máquina? żlos despliega el núcleo central? La respuesta mas sencilla es no.
La principal razón, es que el núcleo puede residir en otra máquina
diferente, con lo cual lo tiene un poco difícil para lanzar el satélite si
no existe un mecanismo fiable de ejecución remota, lo cual está
desaconsejado en la mayoría de las configuraciones de sistemas seguros, o
medio seguros. Para poner en marcha este embrión de aplicación debemos
desplegar a mano los procesos satélite y núcleo. En un sistema de verdad, se
desplegarían como servicios del sistema con la daemonización
correspondiente.
La siguiente pregunta es, żpueden fenecer algún satélite? y si es así,
żqué se hace? Pues si muere un satélite, muerto está, y para ponerlo en
marcha de nuevo, deberemos hacerlo a mano. El núcleo ni siquiera se dará
cuenta, puesto que las tramas UDP tan solo se perderán.
żCómo es por dentro un proceso satélite? Pues tendrá un proceso que
aceptará las peticiones de conexión TCP, y luego desplegará una hebra, si,
el satélite es un servidor multienebrado. Pero cada hebra será muy
sencilla, puesto que no tendrá más que enviar la petición, en una o varias
tramas (según sea el tamańo de la petición), y esperar la respuesta en una
o varias tramas, para enviársela al cliente web.
del proceso núcleo
El proceso núcleo deberá gestionar todas las peticiones de los
satélites, y eso no es nada fácil, sobre todo teniendo en cuenta que dispone
de un único puerto de entrada UDP para todos ellos. Una solución ideada por
un aventajado compańero vuestro propuso generar un clon del núcleo para cada
petición de recurso web. Como es lógico el clon se creará cuando se hayan
recibido todas las tramas de una petición web. A partir de ese momento, el
proceso hijo solo deberá gestionar el contacto con el servidor web y la
respuesta de éste al satélite. Como es lógico, este hijo no deberá leer
del socket de recepción de mensajes de los satélites.
Sería posible una solución asíncrona, en el caso de que cada petición
consistiera de una sola trama UDP. Consiste en lo siguiente:
a) cuando el núcleo recibe una trama de petición, la atiende personalmente,
pero antes despliega un clon exacto que seguirá leyendo tramas del mismo
puerto.
b) cuando la primera copia del núcleo acaba su trabajo podrá hacer dos
cosas
b.1) morirse, si existen otras
copias de él;
b.2) ir al paso a) si no hay más
copia.
Es evidente, que para hacer esto hay que utilizar una variable común que
se irá incrementando y decrementando en función de los clones del núcleo.
Esta variable es una sección crítica, pero żpara qué si no están los
semáforos generalizados? (que por otra parte son fáciles de programar en
Perl).
Como es lógico, estas soluciones no son únicas, y la puerta queda abierta
a otras soluciones, posiblemente más inteligentes.
de la comunicación UDP
La comunicación UDP no tiene conexión, y es de esperar que en esta
aplicación, aparezcan mensajes de todo tipo de orígenes y destinos. Para
subsanar estos problemas, supondremos que la comunicación se desarrolla:
a) sin fallos (estamos en una LAN, y no toleramos fallos); o si!,
según guste usted
b) con tramas ordenadas (la misma respuesta que en el caso anterior);
c) mediante identificadores de proceso que permiten identificar de quién es
la trama y a donde debemos devolverla.
Este último punto no lo voy a comentar, pues además de ser simple,
depende de la solución de los dos epígrafes anteriores.
Este enunciado corresponde a una práctica de Sistemas Distribuidos
de la Ingeniería Técnica en Informática de Gestión y Sistemas de la
Universidad de Valladolid, del curso 2001-2002. Y el derecho de copia y
explotación (c) me pertenece a mí (el profesor de la asignatura) y a mis
alumnos :-)