Todo el mundo puede conducir un automóvil sin necesidad de conocer
cómo funciona un motor de combustión interna y todos los
subsistemas asociados a él. Pero entonces ciertos conceptos como
aprovechamiento de la potencia, compresión, endurecimiento de la
suspensión, motricidad, etc., le serán ajenos y nunca podrá
sacar lo mejor del automóvil. Y si tiene algún problema se
quedará tirado en la carretera.
De la misma manera, no podremos aspirar a que nuestras aplicaciones
de BD funcionen bien si no conocemos la arquitectura del motor de
la BD, el servidor. Es indispensable conocer los factores y parámetros
que influyen en el funcionamiento de nuestro SGBD para poder solucionar
los problemas que se pueden plantear en cuanto nos salgamos de las aplicaciones
estándares y básicas de BD, o en cuanto tengamos algún
problema.
El siguiente curso aborda la arquitectura del SGBD Oracle y da una visión
lo suficientemente profunda del mismo como para que podamos entender cómo
funciona.
Si tienes cualquier sugerencia o encuentras una errata escondida dímelo.
- Terminología
- Un Base de Datos es
- Estructura Lógica-Física de la
BD
- Componentes de la Arquitectura
- Instancia de BD
- Ciclo de Ejecución
- Bibliografía
Términos sobre los que deberías haber oído algo:
- Objeto
- una estructura definida por la BD Oracle y a la que se hacer referencia
en las sentencias SQL dentro de las aplicaciones. La mayoría de
las veces es una tabla, pero las sentencias SQL también pueden hacer
referencia a otros tipos de objetos (vistas, índices, etc.).
- Administrador de la BD, DBA
- es el responsable de la implantación del SGBD y de todo lo relacionado
con la misma: aplicaciones, seguridad, accesibilidad, etc.
- Instancia de la BD
- es la unión de la memoria del ordenador y de los procesos necesarios
para acceder a una BD Oracle.
- Tabla
- es el objeto por excelencia de los SGBD relacionales donde se almacena
la información.
- Espacio de tablas, tablespace
- es el espacio lógico donde se almacena todo objeto de la BD,
y en particular, donde se almacenan las tablas. Físicamente se corresponde
con un conjunto de ficheros de datos en el disco.
- rollback, vueltra atras, deshacer
- es el proceso que el SGBD lleva a cabo para devolver a la BD a un estado
anterior a una modificación.
- Bloque de datos sucio
- parte de la memoria que contiene datos de la BD cuyo valor ha cambiado
con respecto al leído originalmente del fichero de la BD, y que
todavía no ha sido escrito en el fichero de datos.
Una base de datos es un conjunto de archivos de datos y los programas
que los manejan.
Quizás alguien se esperara una definición más elaborada,
pero resulta esencial ver algo tan complejo como una BD desde el punto
de vista más sencillo posible para poder entenderlo.
Al fín, una BD no es más que un programa que almacena
y recupera información de unos ficheros de datos, aunque este proceso
se realice de una manera más o menos complicada y sofisticada.
Dentro de los datos que almacena una BD se pueden distinguir dos clases:
- datos de usuario: que son los que almacenan información de la
aplicación de BD.
- datos del sistema: la información que el sistema necesita para
gestionar los datos del usuario de manera adecuada.
Los datos en Oracle no están distribuidos sin más entre
los distintos ficheros de datos, sino que están sometidos a una
estricta jerarquía dominada por los espacios de tablas o
tablespaces.
3.1
Los Espacios de Tablas, Tablespaces
La BD Oracle está constituida a nivel
- físico: de ficheros (al menos 1)
- lógico: de tablespaces (al menos 1)
y la relación entre ficheros y espacios de tablas es la siguiente:
uno o más espacios de tablas por BD, y cada uno de ellos en uno
o más ficheros de datos.
De esta manera, cuando se crea una tabla se debe indicar el espacio
de tabla al que se destina. Por defecto se depositan en el espacio de tablas
SYSTEM, que se crea por defecto. Este espacio de tablas es el
que contiene el diccionario de datos, por lo que conviene reservarlo para
el uso del servidor, y asignar las tablas de usuario a otro.
Lo razonable y aconsejable es que cada aplicación tenga su propio
espacio de tablas.
Hay varias razones que justifican este modo de organización de
las tablas en espacios de tablas:
- Un espacio de tablas puede quedarse offline debido a un fallo
de disco, permitiendo que el SGBD continúe funcionando con el resto.
- Los espacios de tablas pueden estar montados sobre dispositivos ópticos
si son de sólo lectura.
- Permiten distribuir a nivel lógico/físico los distintos
objetos de las aplicaciones.
- Son una unidad lógica de almacenamiento, pueden usarse para
aislar completamente los datos de diferentes aplicaciones.
- Oracle permite realizar operaciones de backup/recovery a nivel
de espacio de tabla mientras la BD sigue funcionando.
Cuando se crean se les asigna un espacio en disco que Oracle reserva
inmediatamente, se utilice o no. Si este espación inicial se ha
quedado pequeño Oracle puede gestionar el crecimiento dinámico
de los ficheros sobre los que se asientan los espacios de tablas. Esto
elimina la posibilidad de error en las aplicaciones por fallos de dimensionamiento
inicial. Los parámetros de crecimiento del tamaño de los
espacios de tablas se especifican en la creación de los mismos.
Cada espacio de tabla tiene un conjunto de parámetros de
almacenamiento que controla su crecimiento:
- initial: tamaño de la extensión inicial (10k).
- next: tamaño de la siguiente extensión a asignar
(10k).
- minextents: número de extensiones asignadas en el momento
de la creación del espacio de tablas (1).
- maxextents: número máximo de extensiones.
- pctincrease: Porcentaje en el que crecerá la siguiente
extensión antes de que se asigne, en relación con la última
extensión utilizada.
- optimal: Tamańo óptimo declarado para este espacio de
tablas.
- pctused: porcentaje de utilización del bloque por debajo
del cual Oracle considera que un bloque puede ser utilizado para insertar
filas nuevas en él.
- tablespace: nombre del espacio de tablas donde se creará
el segmento.
Se pueden ver los espacios de tablas definidos en nuestra BD con el
comando SQL siguiente:
SQL> select * from user_tablespaces;
3.2
Los Segmentos
Dentro de cada espacio de tabla se pueden almacenar objetos de distinta
naturaleza: tablas, índices, etc. Pero no se pueden mezclar si más.
Necesitamos una manera de separarlos, y eso son los segmentos.
Se pueden almacenar más de un segmento por espacio de tabla.
Un segmento está contenido en su totalidad en un espacio de tabla.
Un segmento está constituido por un conjunto de extensiones, que
no son más que grupos de bloques de disco ORACLE contiguos. Cuando
se borra un segmento, el espacio es devuelto al espacio de tabla.
Todos los datos de la BD están almacenados en segmentos. Y existen
5 tipos de segmentos:
- de datos: almacenan las tablas.
- de índices: permiten un acceso rápido a los datos dependiendo
de la cantidad de los mismos (árboles B). Las consultas que sólo
referencian a columnas indexadas se resuelven en el índice. Establecen
un control de unicidad (los índices son automáticos cuando
se definen claves primarias). Cada índice ocupa un segmento independiente
del segmento de datos y deberían estar en un espacio de tablas distinto
al de los datos, para mejorar el rendimiento.
- de rollback: son objetos internos de la BD que permiten efectuar
la restauración de las transacciones no validadas asegurando la
consistencia en lectura. La estructura de los registros de rollback
es :
- Identificador de la transacción.
- Dirección del bloque donde está la tabla.
- Número de fila.
- Número de columna.
- Valor del dato antiguo (antes de ser modificado).
Son tan importantes que una BD no puede arrancar si no puede acceder
al menos a un segmento de rollback. Si la BD tiene múltiples
espacios de tablas, deben existir al menos dos segmentos de rollback
y cada segmento de rollback debe tener al menos dos extensiones,
reutilizables de manera cíclica. Esto segmentos son un objeto compartido
de la BD, aunque se puede asinar un segmento de rollback particular
a una transacción dada.
- temporales: son creados por Oracle para un uso temporal cuando debe
realizar una ordenación que no le cabe en memoria, y en las operaciones:
create index, order by, group by, distinct, union, intersect, minus. Son
eliminados cuando la sentencia finaliza.
- de bootstrap: Se crea en SYSTEM y contiene definiciones del
Diccionario para sus tablas, que se cargan al abrir la BD. No requiere
ninguna acción por parte del DBA. No cambia de tamaño.
Cada segmento tiene un conjunto de parámetros de almacenamiento
que controla su crecimiento:
- initial: tamaño de la extensión inicial (10k).
- next: tamaño de la siguiente extensión a asignar
(10k).
- minextents: número de extensiones asignadas en el momento
de la creación del segmento (1).
- maxextents: número máximo de extensiones (99).
- pctincrease: Porcentaje en el que crecerá la siguiente
extensión antes de que se asigne, en relación con la última
extensión utilizada (50).
- pctfree: porcentaje de espacio libre para actualizaciones de
filas que se reserva dentro de cada bloque asignado al segmento (10).
- pctused: porcentaje de utilización del bloque por debajo
del cual Oracle considera que un bloque puede ser utilizado para insertar
filas nuevas en él.
- tablespace: nombre del espacio de tablas donde se creará
el segmento.
La tabla que guarda la información de los segmentos de usuario
es user_segments, y se puede visualizar la información
sobre los segmentos con la sentencia SQL siguiente:
SQL> select * from user_segments;
Ya hemos visto cómo se organizan los datos de usuario en la BD
Oracle. Veamos ahora los elementos que configuran la arquitectura de la
BD Oracle. No se pretende con ello realizar un repaso exhaustivo de todos
los elementos de memoria y de los procesos que forman la arquitectura Oracle,
sino enumerar y describir los elementos más importantes.
En la figura siguiente aparecen los diferentes procesos, las estructuras
de memoria y los ficheros que forman la arquitectura de Oracle 7.
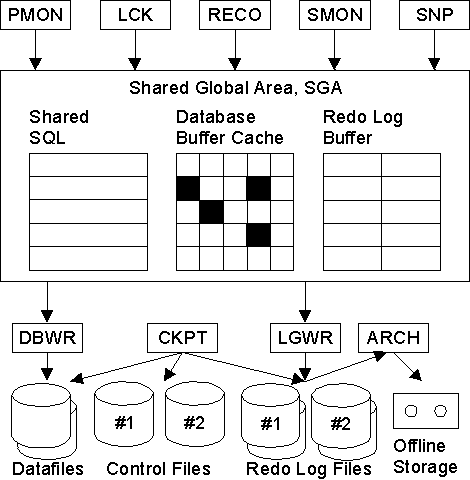
4.1
Elementos de Memoria
Oracle mantiene dos estructuras principales de memoria: el Área
Global de Programa, Program Global Area, PGA; y el Área
Global del Sistema, System Global Area o también Shared
Global Area, SGA.
El PGA es la zona de memoria de cada proceso Oracle. No está
compartida y contiene datos e información de control de un único
proceso.
El SGA es la zona de memoria en la que la BD Oracle guarda información
sobre su estado. Esta estructura de memoria está disponible para
todos los procesos, por eso se dice que está compartida. Está
estructurada en los siguientes elementos principales: Buffers de
la BD, Zona de SQL Compartido y Buffers de Redo Log.
- Buffers de la BD, Database Buffer Cache:
- contiene los bloques de la BD que estan siendo leidos y/o escritos.
Los modificados se llamas bloques sucios.
- Zona de SQL compartido, Shared SQL:
- en esta zona se encuentran las sentencias SQL que han sido analizadas.
El analisis sintáctico de las sentencias SQL lleva su tiempo y Oracle
mantiene las estructuras asociadas a cada sentencia SQL analizada durante
el tiempo que pueda para ver si puede reutilizarlas. Antes de analizar
una sentencia SQL, Oracle mira a ver si encuentra otra sentencia exactamente
igual en la zona de SQL compartido. Si es así, no la analiza y pasa
directamente a ejectutar la que mantinene en memoria. De esta manera se
premia la uniformidad en la programación de las aplicaciones. La
igualdad se entiende que es lexicografica, espacios en blanco y variables
incluidas. El contenido de la zona de SQL compartido es:
- Plan de ejecución de la sentencia SQL.
- Texto de la sentencia.
- Lista de objetos referenciados.
Los pasos de procesamiento de cada petición de análisis
de una sentencia SQL son:
- Comprobar si la sentencia se encuentra en el área compartida.
- Comprobar si los objetos referenciados son los mismos.
- Comprobar si el usuario tiene acceso a los objetos referenciados.
- Si no, la sentencia es nueva, se analiza y los datos de análisis
se almacenan en la zona de SQL compartida.
- Buffers de Redo Log, Redo Log Buffers:
- Oracle escribe todo lo que sucede en la BD en unos ficheros llamados
Redo Logs. Esto está relacionado con la posibilidad de recuperar
la BD de una caida. Pero la escritura en esos ficheros tiene lugar a traves
de estos buffers.
4.2
Elementos de Proceso
Los procesos que intervienen en una BD son de dos tipos:
- procesos de usuario,
- procesos de servidor.
Los procesos de usuario (cliente) responden a la iniciativa del usuario
y sirven para solicitar información de la BD a través de
los procesos de servidor. Un ejemplo de estos procesos es el Sql*Plus.
Los procesos de servidor toman las solicitudes de los procesos de usuario
y se comunican con la BD. Así, estarán muy relacionados con
las diferentes tareas asociadas a la gestión de datos. A saber:
- DBWR, Database Writer
- Es el único proceso que puede escribir en la BD. Esto asegura
la integridad. Se encarga de escribir los bloques de datos modificados
por las transacciones, tomando la información del buffer
de la BD cuando se valida una transacción. Cada validación
no se lleva a la BD física de manera inmediata sino que los bloques
de la BD modificados se vuelcan a los ficheros de datos periodicamente
o cuando sucede algún checkpoint o punto de comprobación:
grabación diferida:
- Los buffers de la BD (bloques del segmento de rollback
y bloques de datos) menos recientemente utilizados son volcados en el disco
continuamente para dejar sitio a los nuevos buffers.
- El bloque del segmento de rollback se escribe SIEMPRE antes
que el correspondiente bloque de datos.
- Múltiples transacciones pueden solapar los cambios en un sólo
bloque antes de escribirlo en el disco.
Mientras, para que se mantenga la integridad y coherencia de la BD,
todas las operaciones se guardan en los ficheros de redo log. El
proceso de escritura es asíncrono y puede realizar grabaciones multibloque
para aumentar la velocidad.
- LGWR, Log Writer
- Coloca la información de los redo log buffers en los
ficheros de redo log. Los redo log buffers almacenan una
copia de las transacciones que se llevan a cabo en la BD. Esto se produce:
- a cada validación de transacción, y antes de que se comunique
al proceso que todo ha ido bien,
- cuando se llena el grupo de buffers de redo log
- cuando el DBWR escribe buffers de datos modificados en disco.
Así, aunque los ficheros de DB no se actualicen en ese instante
con los buffers de BD, la operación queda guardada y se puede reproducir.
Oracle no tiene que consumir sus recursos escribiendo el resultado de las
modificaciones de los datos en los archivos de datos de manera inmediata.
Esto se hace porque los registros de redo log casi siempre tendrán
un tamaño menor que los bloques afectados por las modificaciones
de una transacción, y por lo tanto el tiempo que emplea en guardarlos
es menor que el que emplearía en almacenar los bloques sucios resultado
de una transacción; que ya serán trasladados a los ficheros
por el DBWR. El LGWR es un proceso único, para asegurar la integridad.
Es asíncrono. Además permite las grabaciones multibloque.
- CKPT, Check Point
- Este proceso escribe en los ficheros de control los checkpoints.
Estos puntos de comprobación son referencias al estado coherente
de todos los ficheros de la BD en un instante determinado, en un punto
de comprobación. Esto significa que los bloques sucios de la BD
se vuelcan a los ficheros de BD, asegurándose de que todos los bloques
de datos modificados desde el último checkpoint se escriben
realmente en los ficheros de datos y no sólo en los ficheros redo
log; y que los ficheros de redo log también almacenan
los registros de redo log hasta este instante. La secuencia de puntos
de control se almacena en los ficheros de datos, redo log y control.
Los checkpoints se produce cuando:
- un espacio de tabla se pone inactivo, offline,
- se llena el fichero de redo log activo,
- se para la BD,
- el número de bloques escritos en el redo log desde el
último checkpoint alcanza el límite definido en el
parámetro LOG_CHECKPOINT_INTERVAL,
- cuando transcurra el número de segundos indicado por el parámetro
LOG_CHECKPOINT_TIMEOUT desde el último checkpoint.
Está activo si el parámetro CHECKPOINT_PROCESS
tiene un valor verdadero.
- SMON, System Monitor
- El SMON es el supervisor del sistema y se encarga de todas las recuperaciones
que sean necesarias durante el arranque. Esto puede ser necesario si la
BD se paró inesperadamente por fallo físico, lógico
u otras causas. Este proceso realiza la recuperación de la instancia
de BD. Además límpia los segmentos temporales no utilizados
y compacta los huecos libres contiguos en los ficheros de datos. Este proceso
se despierta regularmente para comprobar si debe intervenir.
- PMON, Process Monitor
- Este proceso restaura las transacciones no validadas de los procesos
de usuario que abortan, liberando los bloqueos y los recursos de la SGA.
Asume la identidad del usuario que ha fallado, liberando todos los recursos
de la BD que estuviera utilizando, y anula la transacción cancelada.
Este proceso se despierta regularmente para comprobar si su intervención
es necesaria.
- ARCH, Archiver
- El proceso archivador tiene que ver con los ficheros redo log.
Por defecto, estos ficheros se reutilizan de manera cíclica de modo
que se van perdiendo los registros redo log que tienen una cierta
antiguedad. Cuando la BD se ejecuta en modo ARCHIVELOG, antes
de reutilizar un fichero redo log realiza una copia del mismo. De
esta manera se mantiene una copia de todos los registros redo log
por si fueran necesarios para una recuperación. Este es el trabajo
del proceso archivador.
- LCK, Lock
- El proceso de bloqueo está asociado al servidor en paralelo.
- RECO, Recoverer
- El proceso de recuperación está asociado al servidor
distribuido. En un servidor distribuido los datos se encuentran repartidos
en varias localizaciones físicas, y estas se han de mantener sincronizadas.
Cuando una transacción distribuida se lleva a cabo puede que problemas
en la red de comunicación haga que una de las localizaciones no
aplique las modificaciones debidas. Esta transacción dudosa
debe ser resuelta de algún modo, y esa es la tarea del proceso recuperador.
Está activo si el parámetro DISTRIBUTED_TRANSACTIONS
tiene un valor distinto de 0.
4.3
Ficheros Involucrados
Aunque ya hemos hablado de ellos en los puntos tratados hasta aquí,
conviene decir algo sobre los ficheros que se encuentran involucrados en
una BD Oracle. Éstos guardan información tanto de los datos
almacenados en la BD como la necesaria para gobernar la propia BD.
- Ficheros de la BD
- en ellos reside la información de la BD. Solo son modificados
por el DBWR. A ellos se vuelcan los bloques sucios de la SGA cuando se
hace una validación o cuando sucede un checkpoint. Las validaciones
de las transacciones no producen un volcado inmediato, sino lo que se conoce
por un commit diferido. Toda actualización se guarda en los
ficheros de redo log, y se lleva a la BD física cuando tenemos
una buena cantidad de bloques que justifiquen una operación de E/S.
Almacenan los segmentos (datos, índices, rollback) de la
BD. Están divididos en bloques (Bloque Oracle = c * Bloque SO),
cada uno de los cuales se corresponde con un buffer del buffer
cache de la SGA. En el bloque de cabecera no se guardan datos de usuario,
sino la marca de tiempo del último checkpoint realizado sobre
el fichero.
- Ficheros redo log
- En ellos se graba toda operación que se efectue en la BD y sirven
de salvaguarda de la misma. Tiene que haber por lo menos 2, uno de ellos
debe estar activo, online, y se escribe en ellos de forma cíclica.
Existe la posibilidad de almacenar los distintos ficheros de redo log
en el tiempo mediante el modo ARCHIVER. Así, se puede guardar
toda la evolución de la BD desde un punto dado del tiempo.
Una opción es la utilización de archivos redo log
multiplexados:
- Permite al LGWR escribir simultaneamente la misma información
en múltiples archivos redo log.
- Se utiliza para protegerse contra fallos en el disco.
- Da una alta disponibilidad a los archivos redo log activos u
online.
Esto se hace definiendo el número de grupos y de miembros
de archivos redo log que van a funcionar en paralelo:
- grupos: funcionan como ficheros redo log normales, uno de ellos
está activo y el resto espera su turno.
- Su nombre lleva incorporado una numeración.
- Deben contener todos el mismo número de miembros.
- miembros: cada escritura de un registro redo log se lleva a
cabo en todos los miembros del grupo activo en ese momento. Los miembros
deben:
- tener el mismo tamaño y el mismo número de secuencia.
- deben tener nombres similares y estar en diferentes discos para proteger
contra fallos de una manera efectiva.
Cuando se produce algún fallo en los ficheros de redo log
o en el proceso LGWR:
- Si la escritura en un fichero redo log falla pero el LGWR puede
escribir al menos en uno de los miembros del grupo, lo hace , ignorando
el fichero inaccesible y registrando un fallo en un fichero de traza o
alerta.
- Si el siguiente grupo no ha sido archivado (modo ARCHIVELOG) antes
del cambio de grupo que lo pone activo, ORACLE espera hasta que se produzca
el archivado.
- Si fallan todos los miembros de un grupo mientras el LGWR trata de
escribir, la instancia se para y necesita recupeción al arrancar.
sucede nada.
Se pueden visualizar los nombres y estado de los ficheros de redo
log:
SVRMGR> select group#, status, substr(member,1,60) from v$logfile;
También se pueden visualizar estadísticas de los ficheros
redo log:
SVRMGR> select group#, sequence#, bytes, members, archived,
2 status, first_change#, first_time from v$logfile;
- Ficheros de control
- mantinen la información física de todos los ficheros
que forman la BD, camino incluido; así como el estado actual de
la BD. Son imprescindibles para que la BD se pueda arrancar. Contienen:
- Infomación de arranque y parada de la BD.
- Nombres de los archivos de la BD y redo log.
- Información sobre los checkpoints.
- Fecha de creación y nombre de la BD.
- Estado online y offline de los archivos.
Debe haber múltiples copias en distintos discos, mínimo
dos, para progerlos de los fallos de disco. La lista de los ficheros de
control se encuentra en el parámetro CONTROL_FILES, que
debe modificarse con la BD parada.
Se puede componer una sentencia SQL que nos muestre todos los ficheros
asociados a una BD. Esta es:
SQL> select 'control' tipo, substr(name,1,70) nombre from v$controlfile
2 union all
3 select 'datos' tipo, substr(name,1,70) nombre from v$datafile
4 union all
5 select 'redo log' tipo, substr(name,1,70) nombre from v$logfile
6 /
Por fín podemos contestar la pregunta ¿qué es una
instancia Oracle?
En términos sencillos, una instancia de BD es una conjunto de
procesos del servidor Oracle que tiene su propio área global de
memoria y una base de datos asociada a ellos.
Así, si sobre una máquina tenemos dos bases de datos,
lab y test, cada una con su propia SGA y un conjunto
de procesos del servidor, entonces esa máquina soporta dos instancias
de BD.
Para no confundir a las BD, cada instancia se identifica mediante el
SID (system identifier). En las máquinas UNIX, esto se almacena
en la variable de entorno ORACLE_SID. Los procesos del servidor
también tienen el SID incluido en su nombre. Así los procesos
asociados a la BD test se llamarán ora_test_dbwr, ora_test_lgwr,
etc.
Para ilustrar el funcionamiento del servidor Oracle vamos a ver el
ciclo de ejecución de una sentencia de lectura y otra de
actualización.
Las sentencias de lectura siguen el siguiente ciclo:
- El proceso cliente pasa la sentencia SQL (SELECT) al
proceso servidor por medio de la SGA.
- Los procesos del servidor buscan en la zona de SQL compartido una
versión ejecutable de la sentencia. Si la encuentran no tienen que
procesarla.
- Se procesa la sentencia SQL y su versión ejecutable se coloca en
la zona de SQL compartido.
- El proceso del servidor intenta leer los bloques de datos de la
SGA. Si no están, se han de leer del fichero de datos. Si los bloques
están en la SGA pero han sido modificados por otro usuario y esa
modificación no ha sido validada aún, el proceso de servidor debe
reconstruir la imagen de la fila a partir de los segmentos de
rollback, para conseguir consistencia en lectura.
- El proceso servidor pasa los datos solicitados al proceso
cliente.
Las sentencias de actualización siguen el siguiente ciclo:
- El proceso cliente pasa la sentencia SQL (UPDATE) al
proceso servidor por medio de la SGA.
- Los procesos del servidor buscan en la zona de SQL compartido una
versión ejecutable de la sentencia. Si la encuentran no tienen que
procesarla.
- Se procesa la sentencia SQL y su versión ejecutable se coloca en
la zona de SQL compartido.
- El proceso del servidor intenta leer los bloques de datos de la
SGA. Si no están, se han de leer del fichero de datos.
- Se registra el valor antiguo de los datos en un segmento de
rollback y se crea un registro redo log.
- Se crea una copia de la transacción en un registro redo
log.
- Se ejecuta la sentencia SQL modificando los datos, y se crea un
registro redo log que así lo refleja.
- El proceso usuario valida la transacción (COMMIT),
registrandose en un registro redo log.
- El LGWR escribe los buffers del redo log en el
disco.
- El servidor indica al cliente que la operación ha sido completada
de manera satisfactoria.
- Se registra la terminación de la transacción en un registro
redo log.
- Se libera la información del rollback, pues ya no va a necesitarse.
Si en el paso 6 el usuario cancela la transacción (ROLLBACK),
se puede utilizar la información de rollback para restablecer
el valor original.
Si sucede algo que impida que la transacción validada por el usuario
pueda llevarse a cabo, se puede utilizar la información contenida en
los registros redo log para rehacer la transacción (a partir
del paso 6).
Como ocurre con todas las transacciones, en algún momento el DBWR
escribe en el archivo de datos la copia de los bloques de datos
modificados que se encuentran en el buffer cache.
Para la elaboración de estos apuntes he utilizado, aparte de
los concimientos que dan la curiosidad y la experiencia, las
siguientes
referencias:
- Oracle: guía de aprendizaje. Michael Abbey y Michael
J. Corey. McGraw-Hill Iberoamericana. 1996.
- Apuntes de los cursos Introducción a Oracle y
Administración de Oracle 7. Release 7.3
de Oracle Educación, 1996.
por lo que doy las gracias a sus autores.